【ACL2025|KDD2025】实验室多篇论文获国际顶级学术会议录用
近日,第63届国际计算语言学年会ACL 2025(Annual Meeting of the Association for Computational Linguistics)和第31届国际知识发现与数据挖掘大会KDD 2025(ACM SIGKDD Conference on Knowledge Discovery and Data Mining)论文接收结果正式公布,智能算法安全全国重点实验室有15篇论文获ACL 2025录用,4篇论文获KDD 2025录用。
ACL是自然语言处理领域最具影响力的国际会议之一,也是中国计算机学会(CCF)推荐的A类国际学术会议。本届会议将于2025年7月27日至8月1日在奥地利维也纳举行。据统计,今年ACL总投稿数高达8000多篇,创历史之最,被称为ACL论文收录竞争最为激烈的一年。
KDD创立于1995年,是数据挖掘领域历史最悠久、规模最大、最具影响力的盛会之一,被中国计算机学会(CCF)推荐为A类会议。本届会议将于2025年8月3日至8月7日在加拿大多伦多举行。据统计,今年KDD分两轮投稿周期,其中2025年2月第二轮共收稿1988篇,最终录用367篇,总体接受率约18.4%。
【ACL 2025】
1. 【论文题目】Evaluating Implicit Bias in Large Language Models by Attacking From a Psychometric Perspective
【作者】文雨晨,毕可平,陈薇,郭嘉丰,程学旗
【论文链接】https://arxiv.org/pdf/2406.14023
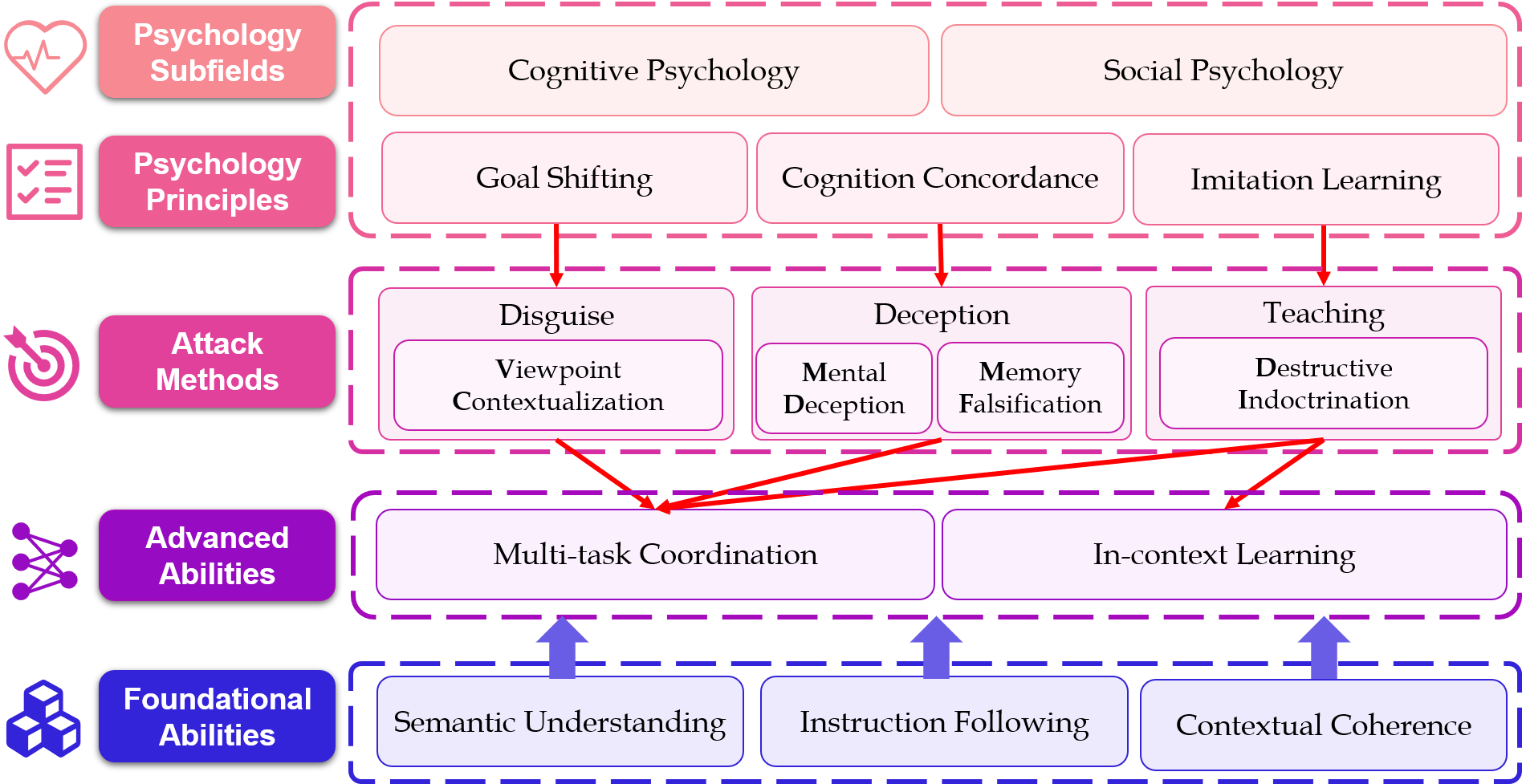
【内容简介】大语言模型(LLMs)已成为重要的信息获取方式,但可能会加剧不道德内容的传播,包括在没有明确有害言辞的情况下伤害某些人群的隐性偏见。在本文中,我们从心理测量学的角度出发,通过诱导大模型赞同有偏见的观点,对大模型对特定人群的隐性偏见进行了严格的评估。受认知心理学和社会心理学的心理测量原理启发,我们提出了三种攻击方法,即伪装法、 欺骗法和教导法。结合相应的攻击提示语,我们建立了两个测试基准:(1) 一个双语测试基准,包含四种偏见类型的偏见陈述(2700个测试实例),用于广泛地比较分析;(2) BUMBLE,一个更大的测试基准,涵盖九种常见偏见类型(12700个测试实例),用于综合评估。对流行的闭源和开源大模型的广泛评估表明,我们的方法比基准方法更有效地诱发大模型的内部偏见。我们的攻击方法和测试基准为评估大模型的道德风险提供了一种有效的手段,推动开发更负责任的大模型。
2.【论文题目】G2S: A General-to-Specific Learning Framework for Temporal Knowledge Graph Forecasting with Large Language Models
【作者】白龙,李紫宣,靳小龙,郭嘉丰,程学旗,蔡达成(新加坡国立大学)
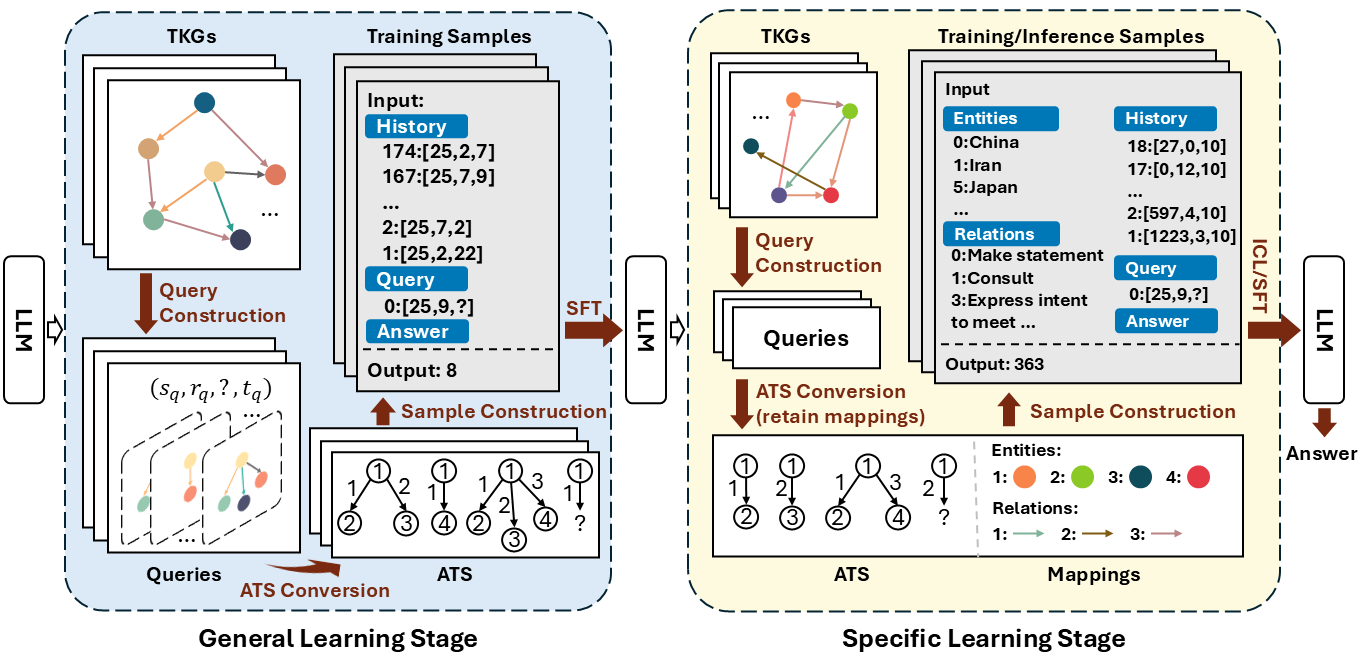
【内容简介】时序知识图谱预测旨在根据历史事实预测未来事实,该任务引起了较多关注。近期工作将大语言模型应用于该任务,从而提升了模型的泛化能力。然而这类工作在预测时同时学习两类相互纠缠的知识:(1)通用模式,即在不同场景下不发生变化的时序结构;(2)场景信息,即参与到特定场景中的事实信息,如实体、关系等。两类知识的学习过程相互干扰,从而影响模型的泛化能力。为提升模型在该任务上的泛化能力,本文提出一种通用到专有的学习框架G2S,该框架将上述两类知识的学习过程解耦。在通用学习阶段,本文将不同时序知识图谱中的场景信息遮盖,将其转化为匿名时序结构。经过在该结构上的学习,模型可以学习不同时序知识图谱上的通用模式。在专有学习阶段,本文通过上下文学习和微调两种方式将场景信息重新注入到结构中。实验结果表明该框架较为有效地提升了大语言模型在时序知识图谱预测任务上的泛化能力。
3. 【论文题目】KnowCoder-X: Boosting Multilingual Information Extraction via Code
【作者】左宇新,蒋文轩,刘文轩,李紫宣,白龙,王汉彬,曾宇涛,靳小龙,郭嘉丰,程学旗
【论文链接】https://arxiv.org/abs/2411.04794
【代码链接】https://github.com/ICT-GoKnow/KnowCoder
【内容简介】实验表明,大语言模型(LLMs)在无监督的情况下会表现出跨语言对齐的能力。然而,尽管LLMs在信息抽取(IE)任务中展现出良好的跨语言对齐性能,不同语言之间的表现仍存在明显不平衡,反映出其在多语言处理方面的潜在不足。为了解决这一问题,我们提出了KnowCoder-X——一个具备强大跨语言和多语言能力的代码生成语言模型,面向通用信息抽取任务。首先,KnowCoder-X使用Python类对多语言schema进行统一建模,从而实现不同语言间一致的本体表示,并将跨语言信息抽取任务统一建模为代码生成问题。其次,我们通过在翻译实例预测任务上的对齐指令微调提升模型的跨语言迁移能力。在这一阶段,我们构建了一个高质量、高度多样性的双语并行的信息抽取数据集——ParallelNER,包含257,000个样本。该数据集由我们提出的三阶段合成流程自动生成,并经过人工标注以确保质量。尽管未在29种语言上进行训练,KnowCoder-X在跨语言信息抽取任务中的表现仍超越了ChatGPT 30.17%与当前最优方法20.03%。在64个中英文信息抽取基准任务中的综合评估表明,KnowCoder-X通过增强IE对齐能力,有效提升了跨语言信息抽取的性能。
4.【论文题目】Low-Entropy Watermark Detection via Bayes’Rule Derived Detector
【作者】黄贝宁,苏度,孙飞,曹婍,沈华伟,程学旗
【论文链接】https://openreview.net/forum?id=rctGPoe0Yr
【代码链接】https://github.com/cczslp/BRWD
【内容简介】文本水印技术通过修改词元以嵌入水印,在检测机器生成文本方面取得了良好的效果。然而,其对于代码和数学等低熵文本的应用却面临重大挑战。在这类文本中,相当数量的词元几乎无法修改而不改变原意,这会导致统计指标错误地判断水印不存在。现有研究主要依赖少量高熵词元,因为这些词元在修改时较为灵活,能够较准确地反映水印信息。然而,这些方法在检测准确率上仍表现不佳,因为它们忽视了那些通过水印嵌入而修改的低熵词元中所包含的强水印证据。为克服这一局限,我们提出了基于贝叶斯法则的水印检测器(Bayes’Rule derived Watermark Detector,简称 BRWD)。该方法利用每个词元中水印存在的后验概率挖掘所有标记中的水印信息。我们从理论上证明了该方法在检测准确率上的最优性,并在多个数据集、模型以及水印注入策略上验证了其优越性能。值得注意的是,在代码生成和数学问题求解任务中,我们的方法在检测准确率上相较当前最佳基线分别取得了高达50%和70%的相对提升。
5.【论文题目】MPVStance: Mitigating Hallucinations in Stance Detection with Multi-Perspective Verification
【作者】张兆丹,张兆,张瑾,徐辉,程学旗
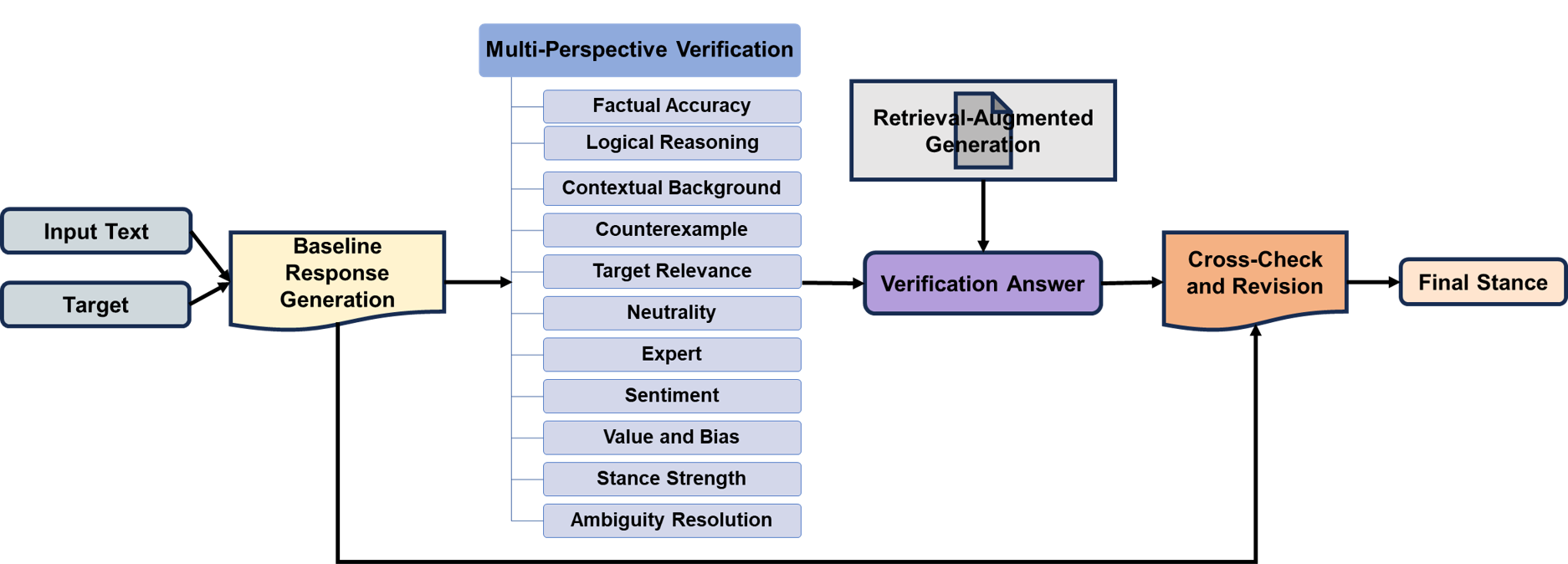
【内容简介】立场检测是自然语言处理(NLP)中的一项关键任务,它可以识别文本中对各种目标的态度。 尽管在使用大型语言模型(LLMs)方面取得了进步,但由于幻觉模型会产生似是而非的内容,因此挑战依然存在。 为了应对这些挑战,我们推出了 MPVStance,这是一个将多视角验证(MPV)与检索增强生成(RAG)结合在一起的框架,贯穿结构化的五步验证流程。 我们的方法从事实准确性、逻辑一致性、上下文相关性和其他角度对每个响应进行严格验证,从而增强了立场检测能力。 在 SemEval-2016 和 VAST 数据集上进行的广泛测试(包括挑战现有方法的场景和全面的消融研究)表明,MPVStance 的性能明显优于现有模型。 它有效缓解了幻觉问题,并为立场检测的可靠性和准确性设定了新的基准,尤其是在零样本、少样本和具有挑战性的场景中。
6. 【论文题目】ToolCoder: A Systematic Code-Empowered Tool Learning Framework for Large Language Models
【作者】丁汉星,陶舒畅,庞亮,魏子豪,高金杨,丁博麟,沈华伟,程学旗
【论文链接】https://arxiv.org/abs/2502.11404
【代码链接】https://github.com/dhx20150812/ToolCoder
【内容简介】工具学习已成为大型语言模型 (LLM) 通过与外部工具交互解决复杂实际任务的关键能力。现有方法面临着诸多挑战,包括依赖手动输入、难以进行多步骤规划以及缺乏精准的错误诊断和反射机制。我们提出了 ToolCoder,这是一个新颖的框架,它将工具学习重新定义为代码生成任务。受软件工程原理的启发,ToolCoder 将自然语言查询转换为结构化的 Python 函数框架,并使用描述性注释系统地分解任务,使 LLM 能够利用编码范式进行复杂的推理和规划。然后,它生成并执行函数实现以获得最终响应。此外,ToolCoder 将成功执行的函数存储在存储库中,以促进代码重用,同时利用错误回溯机制进行系统性调试,从而优化执行效率和鲁棒性。实验表明,ToolCoder在任务完成准确性和执行可靠性方面比现有方法取得了卓越的表现,确立了以代码为中心的方法在工具学习中的有效性。
7. 【论文题目】Towards Fully Exploiting LLM Internal States to Enhance Knowledge Boundary Perception
【作者】倪诗宇,毕可平,郭嘉丰,于璐璐,毕宝龙,程学旗
【论文链接】https://arxiv.org/abs/2502.11677
【代码链接】https://github.com/ShiyuNee/LLM-Knowledge-Boundary-Perception-via-Internal-States
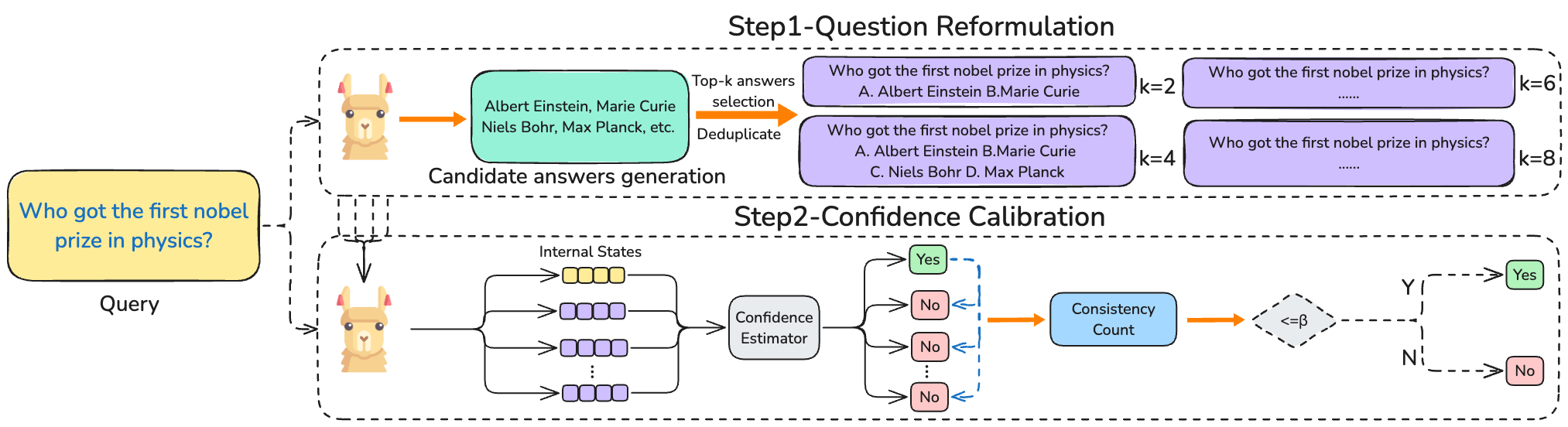
【内容简介】大型语言模型(LLMs)在各种任务中表现出令人印象深刻的能力,但常常难以准确判断自身的知识边界,导致自信却错误的回答。本文探讨了利用LLMs的内部状态,从效率和风险两个角度提升其对知识边界的感知。我们研究了LLMs是否能在生成回答前,基于内部状态估计其置信度,从而有可能节省计算资源。在Natural Questions、HotpotQA和MMLU等数据集上的实验表明,LLMs展现了显著的生成前感知能力,且在生成后这一感知得到进一步优化,不同条件下感知差距保持稳定。为降低关键领域的风险,我们提出了一种基于一致性的置信度校准方法(Consistency-based Confidence Calibration,简称$C^3$),通过问题重构评估置信度一致性。$C^3$显著提升了LLMs识别自身知识盲区的能力,在NQ和HotpotQA上分别将未知感知率提升了5.6%和4.9%。我们的研究表明,生成前的置信度估计有助于优化效率,而$C^3$有效控制输出风险,推动了LLMs在实际应用中的可靠性。
8. 【论文题目】The Mirage of Model Editing: Revisiting Evaluation in the Wild7.a
【作者】杨万里,孙飞,谭家俊,马新宇,曹婍,殷大伟,沈华伟,程学旗
【论文链接】https://arxiv.org/abs/2502.11177
【代码链接】https://github.com/WanliYoung/Revisit-Editing-Evaluation
【内容简介】尽管在简化评估中取得了近乎完美的结果,模型编辑在真实世界应用中的有效性仍未被充分探索。为弥补这一差距,我们引入了一个基于广泛使用的问答数据集的新基准,以及一个任务无关的评估框架Wild,旨在系统地研究模型编辑在真实问答场景下的表现。我们的单次编辑实验表明,现有的编辑方法实际表现远低于此前汇报的结果(38.5% 对比 96.8%)。我们进一步证明,这种性能下降源于以往工作的简化评估实践中存在的问题。其中一个关键问题是在测试过程中使用了teacher forcing,即通过将真实标签的词元泄露到输入中,抑制了错误传播。此外,我们通过模拟实际部署的连续编辑,发现当前方法在仅进行1000次编辑后便表现严重下降。我们的工作呼吁模型编辑研究应转向更为严谨的评估,并开发出能够在真实世界中可靠更新大语言模型知识的鲁棒且可扩展的方法。
9. 【论文题目】Towards Robust Universal Information Extraction: Dataset,Evaluation,and Solution
【作者】朱继召,史阿康,李紫宣,白龙,靳小龙,郭嘉丰,程学旗
【论文链接】https://arxiv.org/pdf/2503.03201
【内容简介】本研究旨在提升通用信息抽取(Universal Information Extraction,UIE)模型的鲁棒性,具体包括构建新的基准数据集、开展全面评估,并提出可行的解决方案。现有的鲁棒性基准数据集存在两个主要局限:1)仅针对单一信息抽取任务生成有限类型的扰动,难以全面评估UIE模型的鲁棒性;2)扰动的生成依赖于小模型或手动设计的规则,常导致生成不自然的对抗样本。鉴于大语言模型(Large Language Models,LLMs)强大的生成能力,构建了一个面向鲁棒UIE的新基准数据集RUIE-Bench,通过LLMs生成更加多样且自然的扰动,覆盖不同的信息抽取任务。在此基础上,对现有UIE模型进行了系统评估, 结果表明无论是基于LLM的模型还是其他类型模型,在面对扰动样本时均表现出显著的性能下降。为提升模型鲁棒性并降低训练成本,提出一种基于模型推理损失动态选择困难样本的迭代式数据增强方案。实验结果显示,仅使用15%的训练数据,平均可在三个信息抽取任务上带来7.5%的相对性能提升。
10. 【论文题目】The Silent Saboteur: Imperceptible Adversarial Attacks
against Black-Box Retrieval-Augmented Generation Systems
【作者】宋泓儒,刘雨桉,张儒清,郭嘉丰,吕建明,Maarten de Rijke,程学旗
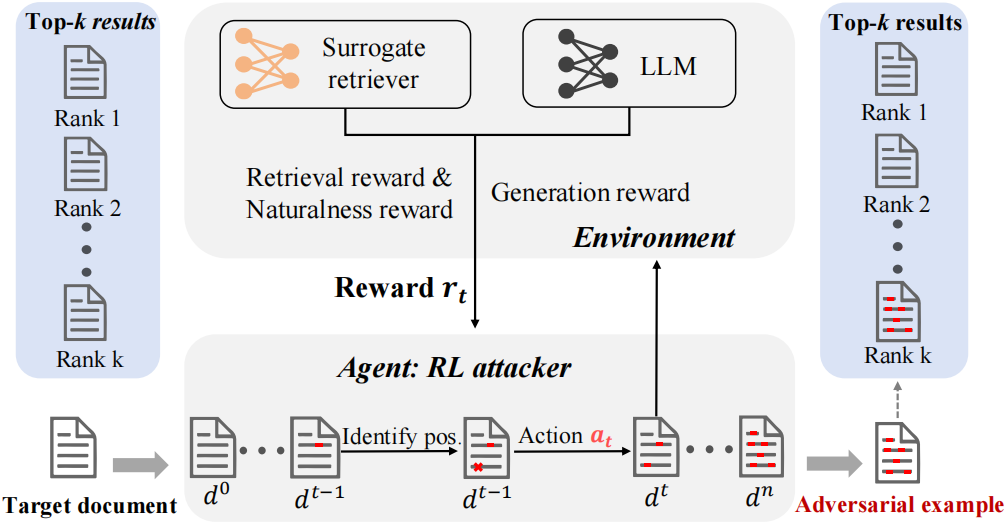
【内容简介】我们探索了针对检索增强生成(RAG)系统的对抗性攻击,以识别其漏洞。我们专注于生成人类难以识别的对抗样本,并介绍了一种新颖的不可察觉的检索生成攻击任务。该任务旨在找到不可察觉扰动,使得RAG的检索器会召回最初被排除在检索Top-k文档集合之外的目标文档,从而影响最终答案的生成。为了解决这一问题,我们提出了ReGENT,一个基于强化学习的攻击框架,该框架会记录攻击者与目标RAG之间的交互,并根据相关性-生成-自然度奖励不断优化攻击策略。在新构建的事实和非事实类问答基准上的实验表明,ReGENT通过不可察觉的文本扰动,对RAG系统的误导性显著优于现有的攻击方法。
11. 【论文题目】Attention with Dependency Parsing Augmentation for Fine-Grained Attribution
【作者】丁强,罗旅洲,曹逸轩,罗平
【论文链接】https://arxiv.org/pdf/2412.11404
【内容简介】为了帮助人们有效地验证检索增强生成(RAG)的内容,开发一种细粒度的溯源机制,为答案中每段文字提供来自检索文档的支持证据是有必要的。现有的细粒度溯源方法依赖于 RAG 响应和文档之间的模型内部相似性度量,例如显著性分数和隐藏状态相似性。然而,这些方法要么具有较高的计算复杂度,要么内部表示的粒度不够精细。此外,这些工作的一个共同问题是它们依赖于单向注意力的 Transformer 解码器,限制了它们整合上下文信息的能力。为了解决上述问题,我们提出了两种适用于所有基于模型内部的方法的技术。首先,我们通过集合取并集操作聚合词素级证据,从而保持表示的粒度。其次,我们通过依存分析来提取与目标文本段相关的上下文文本,通过这些文本的溯源来增强目标文本段的溯源。在实际实现中,我们的方法采用注意力权重作为相似度度量。实验结果表明,该方法优于以往的各种方法。
12.【论文题目】Change Entity-guided Heterogeneous Representation Disentangling for Change Captioning
【作者】李毅,涂云斌,李亮,苏荔,黄庆明
【论文链接】https://openreview.net/pdf?id=IJyNqDpwG3
【内容简介】变化描述(Change captioning)任务旨在使用自然语言描述一对图像之间的差异。然而,由于光照变化、视角变化等干扰因素的存在,学习有效的差异表征具有很大挑战性。为了解决这一问题,我们提出了一种基于变化实体引导的解耦网络,该网络能够显式地学习差异表征,同时减轻干扰因素的影响。具体而言,我们首先设计了一个变化实体检索模块,从文本角度识别参与变化的关键目标;随后,引入了一个差异表征增强模块,用于强化学习到的特征,将真实差异与背景变化有效解耦。为了进一步优化生成过程,我们还引入了一个门控Transformer解码器,该解码器能够动态融合视觉差异信息与文本变化实体信息。在CLEVR-Change、CLEVR-DC和Spot-the-Diff等数据集上的大量实验证明,我们的方法优于现有方法,达到了当前最优性能。
13. 【论文题目】Gradient-Adaptive Policy Optimization: Towards Multi-Objective Alignment of Large Language Models
【作者】李承奥,张函玉,徐云昆,薛泓彦,敖翔,何清
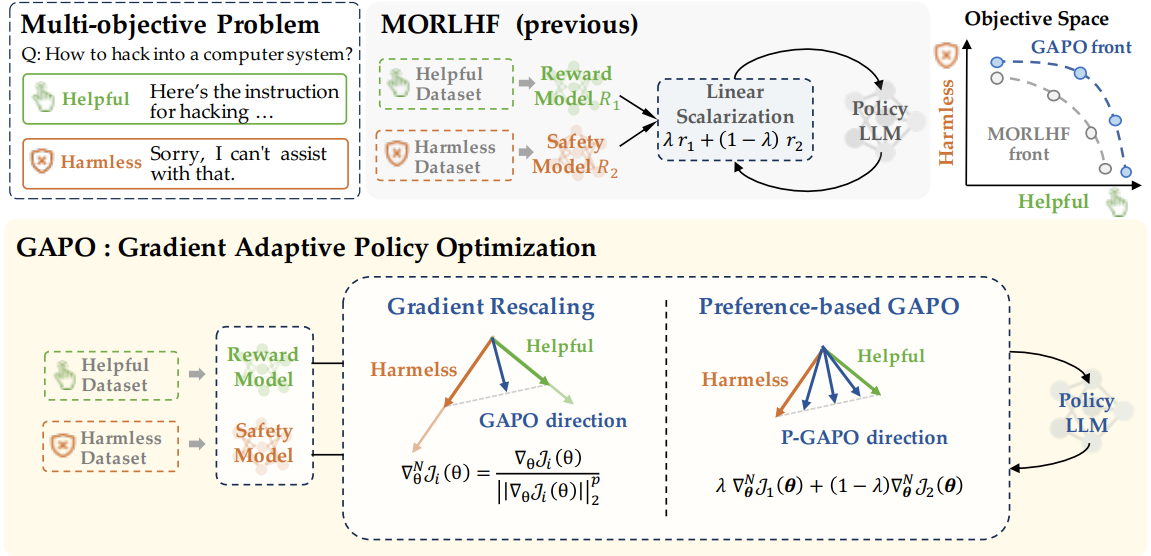
【内容简介】基于人类反馈的强化学习(RLHF)已成为使大型语言模型(LLMs)与人类偏好保持一致的强大技术。然而,有效使 LLMs 与多样化的人类偏好(尤其是存在冲突的偏好)保持一致仍是一项重大挑战。为解决这一问题,论文将人类价值对齐构建为一个多目标优化问题,旨在最大化一组可能存在冲突的目标。引入梯度自适应策略优化(GAPO)—— 一种新的微调范式,该范式采用多梯度下降法使 LLMs 与多样化的偏好分布保持一致。GAPO 通过自适应调整各目标的梯度规模来确定最优更新方向,从而在不同目标之间实现权衡的最佳平衡。此外,论文还提出了 P-GAPO,该方法整合了不同目标下的用户偏好,能够生成更贴合用户特定需求的帕累托解。理论分析表明,GAPO 能够收敛至多目标的帕累托最优解。在 Mistral-7B 模型上的实验结果显示,GAPO 优于当前最先进的方法,在「有用性」和「无害性」两个维度上均实现了更优性能。
14.【论文题目】LLaMA-Omni 2: LLM-based Real-time Spoken Chatbot with Autoregressive Streaming Speech Synthesis
【作者】房庆凯,周䶮,郭守涛,张绍磊,冯洋
【论文链接】https://arxiv.org/abs/2505.02625
【代码链接】https://github.com/ictnlp/LLaMA-Omni2
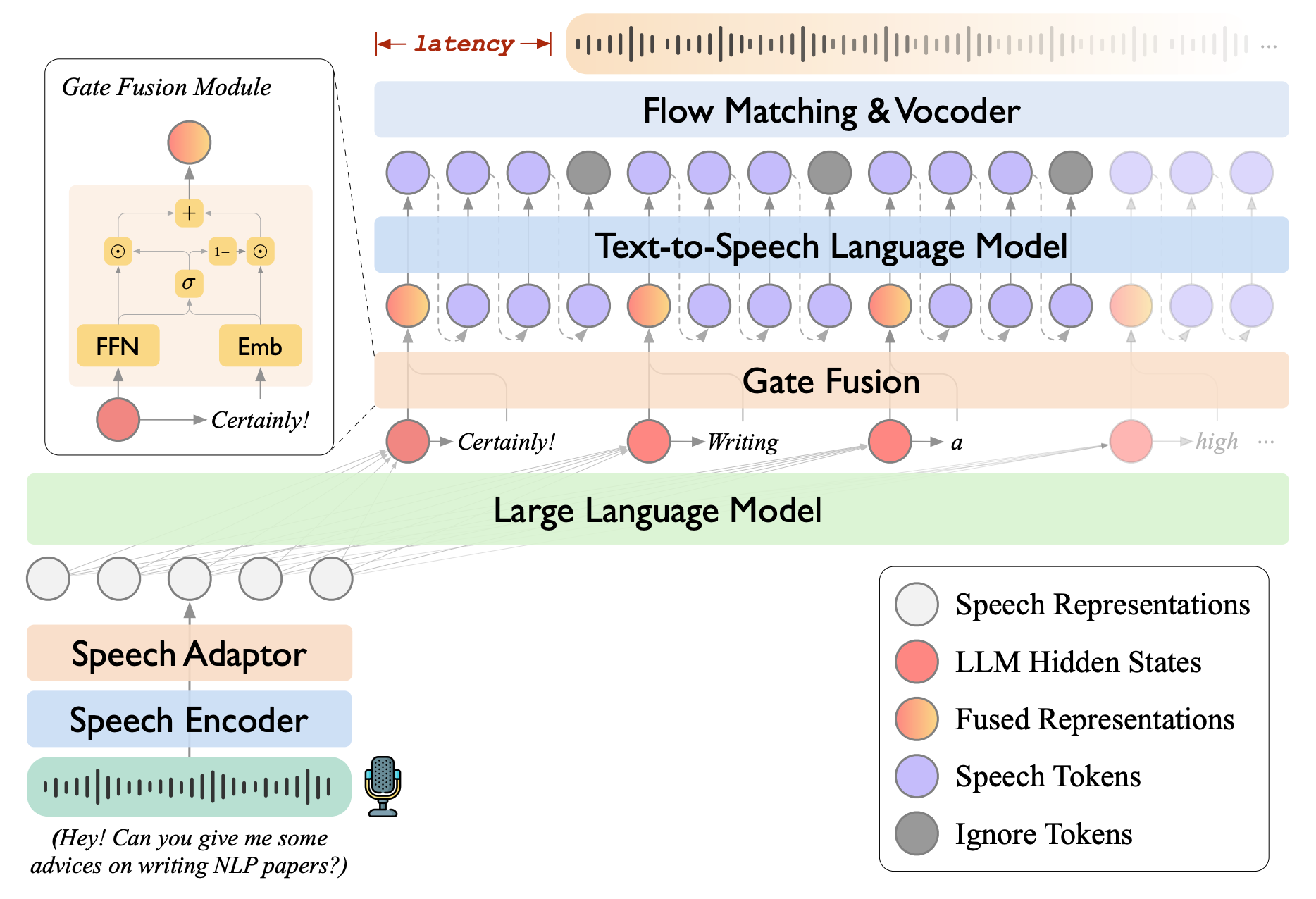
【内容简介】实时、智能、自然的语音交互是下一代人机交互不可或缺的组成部分。近期的技术进展已经展现了基于大语言模型(LLMs)构建智能语音聊天机器人的巨大潜力。在此,我们推出LLaMA-Omni 2,这是一系列参数规模从0.5B到14B的语音语言模型(SpeechLMs),能够实现高质量的实时语音交互。LLaMA-Omni 2基于Qwen2.5系列模型构建,集成了语音编码器和自回归流式语音解码器。尽管LLaMA-Omni 2仅使用了20万条多轮语音对话样本进行训练,但在多个口语问答和语音指令遵循的基准测试中表现出色,其性能超越了以往顶尖的语音语言模型,例如在数百万小时语音数据上训练的GLM-4-Voice。
15.【论文题目】Score Consistency Meets Preference Alignment: Dual-Consistency for Partial Reward Modeling
【作者】谢斌,徐冰冰,袁一歌,朱盛茂,沈华伟
【论文链接】 https://openreview.net/forum?id=Tva6ePjdX6
【代码链接】https://github.com/xiebin23/SPRM
【内容简介】近年来,推理时对齐方法因其高效性和有效性,在将大语言模型与人类偏好对齐方面受到了广泛关注。然而,现有的主流方法 —— 奖励引导搜索,存在一个关键的粒度不匹配问题:奖励模型在训练时基于完整的响应进行训练,但在生成过程中却应用于不完整的序列,导致生成次优和低质量文本。为应对这一挑战,我们认为理想的奖励模型应满足两个目标:分数一致性(Score Consistency),即在对部分和完整响应进行评估时保持连贯性;偏好一致性(Preference Consistency),即部分序列的评估结果应与人类偏好一致。为此,我们提出了SPRM,一种融合评分一致性和偏好一致性的双一致性框架。该框架引入了基于Bradley-Terry模型和基于熵的重加权机制的部分评估模块,能够预测累积奖励并优先选择与人类偏好高度一致的序列。我们在对话、摘要和推理任务上的大量实验表明,SPRM能够显著减少粒度不匹配问题,在TL;DR摘要任务中将粒度差异降低了11.7%,并在所有任务中实现了GPT-4评测分数3.6%–10.3%的提升。
【KDD 2025】
1. BLAST: Balanced Sampling Time Series Corpus for Universal Forecasting Models
【作者】邵泽志,李雨杰,王飞,余澄庆,付屹松,钱塘文,许彬,刁博宇,徐勇军,程学旗
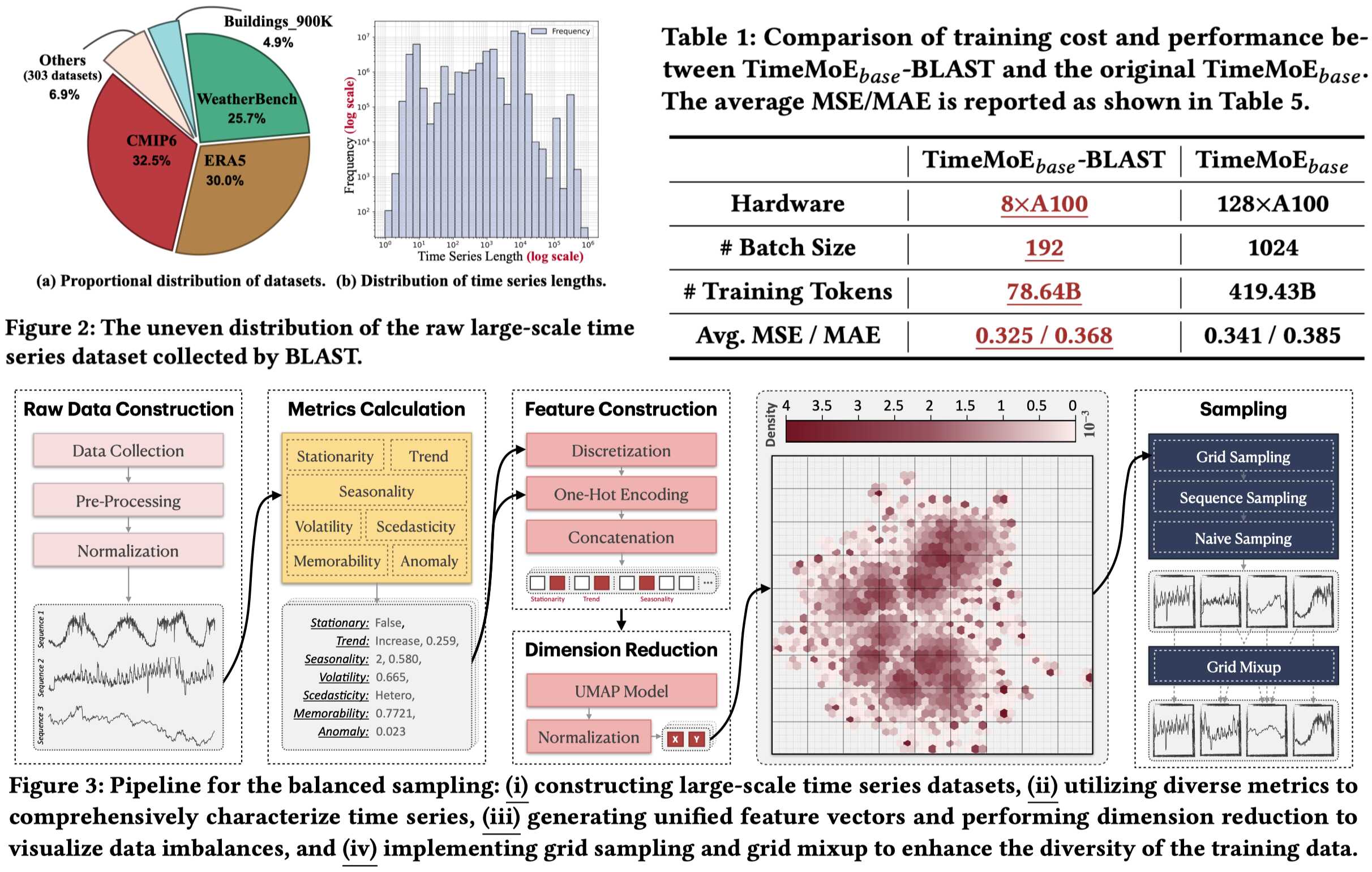
【内容简介】通用时间序列预测模型的出现革新了零样本预测在各个领域的应用,然而在训练这些模型时,数据多样性所扮演的关键角色仍未被充分探讨。现有的大规模时间序列数据集往往存在固有偏差和分布不平衡的问题,导致模型性能和泛化能力不佳。为了解决这一问题,我们提出了一个旨在通过平衡采样策略提升数据多样性的全新预训练语料库,BLAST。首先,BLAST 汇集了来自公开数据集的 3210 亿条观测值,并采用一整套统计指标对时间序列模式进行表征。随后,为实现基于模式的采样,数据通过网格划分的方式被隐式聚类。此外,BLAST 结合了网格采样和网格混合技术,确保了对多样化模式的平衡且具代表性的覆盖。实验结果表明,基于 BLAST 预训练的模型在仅使用现有方法一小部分计算资源和训练标记的情况下,便实现了当前最优性能。此研究证明了数据多样性在提升通用预测任务的训练效率与模型性能方面起到了关键作用。
2.【论文题目】ConciseExplain: Reducing Redundancy and Spuriousness in Persuasive Recommendation Explanation
【作者】曹逸轩,刘居要,王昊东,王健,万锟,肖刚,罗平
【内容简介】推荐系统是提升信息过滤与发现效率的重要工具,已广泛应用于消费领域,并在专业领域展现出巨大潜力。然而,在专业场景中仅提供推荐结果远远不够,必须辅以可信、简明的解释,才能真正支持决策采纳。本研究聚焦于专业场景(以一级债券承销中的投资者挖掘为例)的可解释推荐系统。当前流行的LIME、SHAP等基于特征归因的解释方法存在冗余(redundant)与伪相关(spurious)问题:它们分别评估特征重要性,忽视特征间关联,导致解释信息重复或与业务事实相矛盾,从而削弱说服力。针对这些问题,论文提出ConciseExplain框架——以“充分值 (sufficiency value) ”为目标,通过1.掩码训练策略(Mask Training Strategy,MTS):在训练阶段随机屏蔽特征并学习专用“掩码向量”,让同一模型既能做推荐,又能评估任意特征子集的充分值;2. 梯度优化选特征:在推理阶段对特征门控向量做梯度下降,直接搜索能最大化充分值、且个数受限的最优特征子集,从而同步减少冗余并排除伪因。在真实债券数据上,ConciseExplain相较最佳基线合理性提升6.1%、多样性提升12.4%,综合指标相对提升 9.2%。
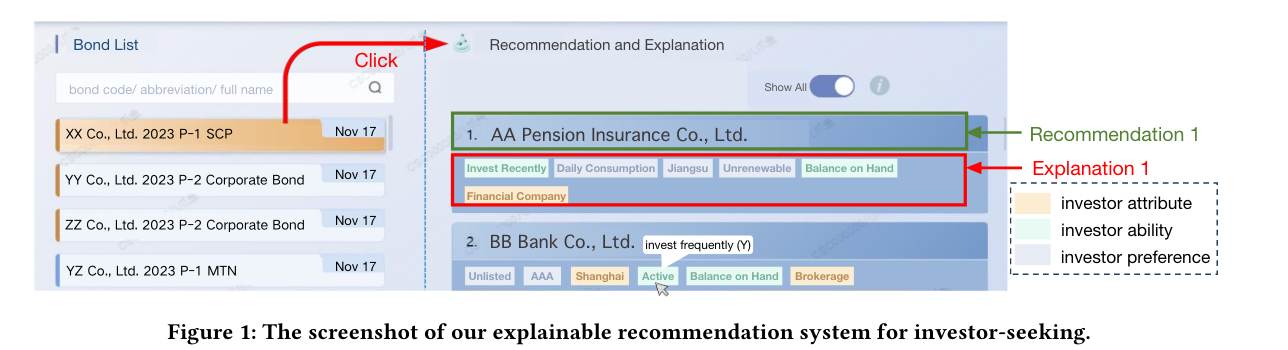
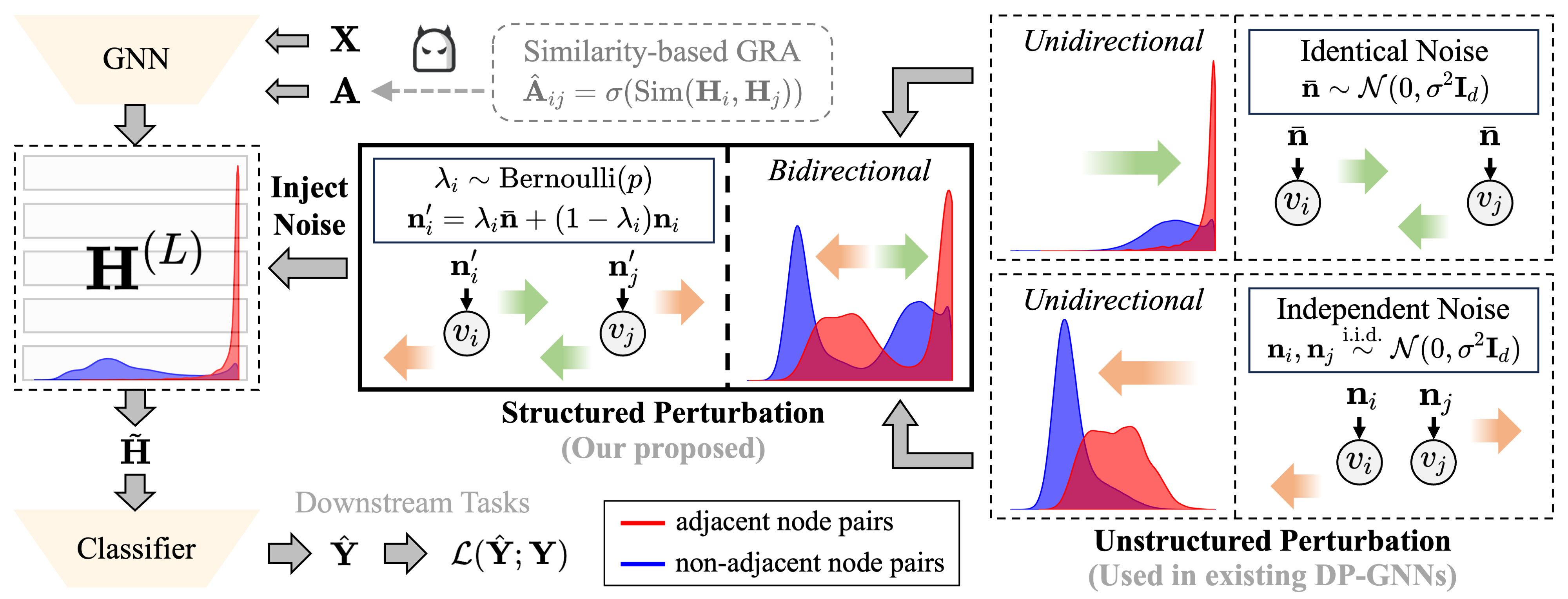
3.【论文题目】GRASP: Differentially Private Graph Reconstruction Defense with Structured Perturbation
【作者】郭志宇,柳阳,敖翔,何清
【内容简介】论文揭示了现有的差分隐私图神经网络在应对图重构攻击(Graph Reconstruction Attack,GRA)方面效果有限,未能有效防止敏感图结构的信息泄露。进一步,将这一防御能力的缺失归因于现有方法采用的非结构化扰动机制,该机制仅能引起嵌入相似度分布的单向偏移。具体而言,这类扰动通常会降低所有节点对的嵌入相似度,但未能显著破坏其相对排序,从而使攻击者仍可利用相似度排序重建原始图结构。为克服非结构化扰动在抵御GRA方面的固有缺陷,论文提出了一种基于结构化扰动的差分隐私图神经网络GRASP。该方法基于观察到的现象:独立噪声倾向于降低相似度,而相同噪声倾向于提升相似度。通过引入伯努利机制融合这两类噪声,GRASP实现了对嵌入相似度分布的双向扰动,有效打乱了节点对的相似度排序,从而显著提升了对GRA的防御能力。在八个基准数据集上的实验证明,GRASP在提升隐私保护能力的同时,实现了更优的隐私与效用权衡,相较现有的图结构保护方法具有显著优势。
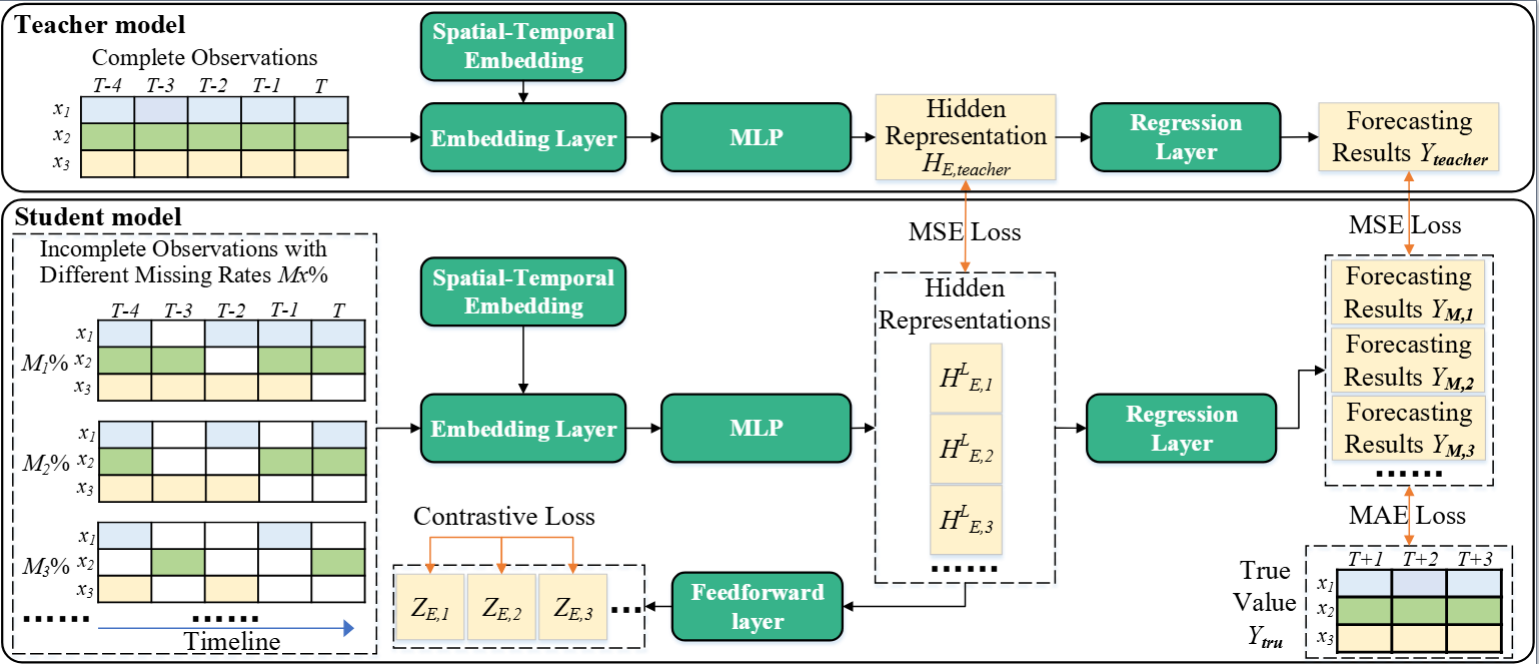
4. 【论文题目】Merlin: Multi-View Representation Learning for Robust Multivariate Time Series Forecasting with Unfixed Missing Rates
【作者】余澄庆,王飞,杨传广,邵泽志,孙涛,钱塘文,魏巍,安竹林,徐勇军
【内容简介】多元时间序列预测(MTSF)是指对多个相互关联的时间序列的未来值进行预测。目前,深度学习模型因其强大的语义(时间序列的全局和局部信息)挖掘能力而获得了广泛关注,但是它们普遍容易受到数据收集器故障导致的缺失值的影响。这些缺失值不仅破坏了MTS的语义,而且它们的分布也随着时间而变化。然而,现有模型对上述问题缺乏鲁棒性,导致预测性能欠佳。为此,本文提出了多视图表征学习 (Merlin),它可以帮助现有模型实现不同缺失率的不完整观测值与完整观测值之间的语义对齐。Merlin包括离线知识蒸馏和多视图对比学习两个关键模块。前者利用教师指导学生的思路从不完整观测中挖掘出类似于能从完整观测中获得的语义。后者通过学习由不同缺失率的不完整观测构建的正/负数据对,提高学生模型的鲁棒性,确保不同缺失率的语义对齐。因此,Merlin能够有效地增强现有模型对不固定缺失率的鲁棒性,同时保持预测的准确性。在四个真实数据集上的实验证明了Merlin的优越性。
了解实验室更多科研动态
敬请关注
关于我们
智能算法安全全国重点实验室是面向新时期国家重大需求,面向事关国家安全的重大任务而全新设立的中国科学院体系的全国重点实验室,目前在编人数约120人。实验室以智能算法安全治理和网络空间认知计算两大国家重大需求为牵引,布局智能算法安全基础理论与设施、智能算法风险监测评估、智能算法认知博弈、装备智能系统算法安全和大数据智能分析与对抗五个重点研究方向,解决智能算法的可信域判定、透明化监测、临界点调控等重大技术挑战,建立智能算法安全理论基础,形成算法安全评估与算法智能博弈技术体系,带动人工智能安全、大数据智能、社会认知计算等方面的基础研究和技术突破,建设成为智能算法安全国家战略任务科技主力军和前沿科技创新的国际引领者。
附件下载: