实验室8篇论文获LREC-COLING 2024录用
LREC-COLING 2024会议(The 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation)由计算语言学领域的ELRA语言资源协会(ELRA)和国际计算语言学委员会(ICCL)联合组织,将于5月20-25日在意大利都灵召开。智能算法安全重点实验室(中国科学院)8篇论文获LREC-COLING 2024录用。
DRAMA: Dynamic Multi-Granularity Graph Estimate Retrieval over Tabular and Textual Question Answering
作者:袁瑞泽,敖翔,曾理,何清
内容简介:TableTextQA任务旨在从结合了表格和链接文本的混合数据中找到与问题相关的答案,这一任务正受到越来越多的关注。已经提出的基于表格行的方法显示出了显著的有效性。然而,它们存在一些限制:(1)缺乏各行之间的交互;(2)输入长度过长;(3)在多跳QA任务中存在难以有效推导的复杂推理步骤。因此,本文提出了一种新方法:基于动态图估计的多粒度检索(Dynamic Multi-Granularity Graph Estimate Retrieval,DRAMA)。该方法引入了多行之间的交互机制。具体来说,利用知识库存储每个粒度特征,从而便于构建包含表格及链接文本结构信息的异构图。此外,本文设计了动态图注意力网络(DGAT)来评估多跳问题中的问题关注度转移,并动态消除不相关信息的连接。在广泛使用的HybridQA和TabFact公开数据集上,该研究取得了SOTA的实验结果。
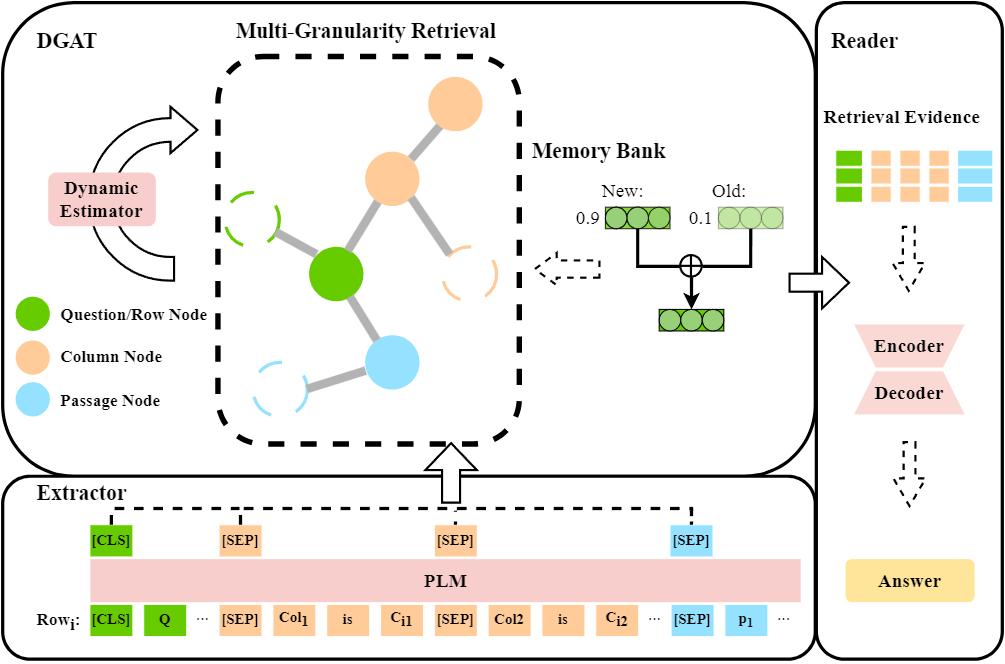
图1: DRAMA模型结构图
★
Distillation with Explanations from Large Language Models
作者:张函玉,王希廷,敖翔,何清
内容简介:自然语言形式的解释对于人工智能模型的可解释性至关重要。然而,训练模型来生成高质量的自然语言解释是一个挑战,因为训练需要大量人类编写的解释,这意味着需要很高的成本。目前,ChatGPT和GPT-4这样的大语言模型在各种自然语言处理任务上取得了显著进展,大模型在作答的同时也提供了相应答案的解释,利用大模型来进行数据标注是一个更经济的选择。然而,一个关键的问题是大模型提供的答案并不完全准确,可能会给任务输出和解释生成引入噪声。为了解决这个问题,本文提出了一种新的机制,即利用大模型的解释辅助蒸馏。研究观察到,尽管大模型生成的答案可能不正确,但它们的解释与答案往往是一致的。利用这种一致性,本文结合了真实标签和大模型生成的答案和解释,通过一致性模型,来同时生成更准确的答案和相应解释。实验结果表明,本文的方法可以提高作答的准确率,并且可以生成与模型作答更加一致的解释。
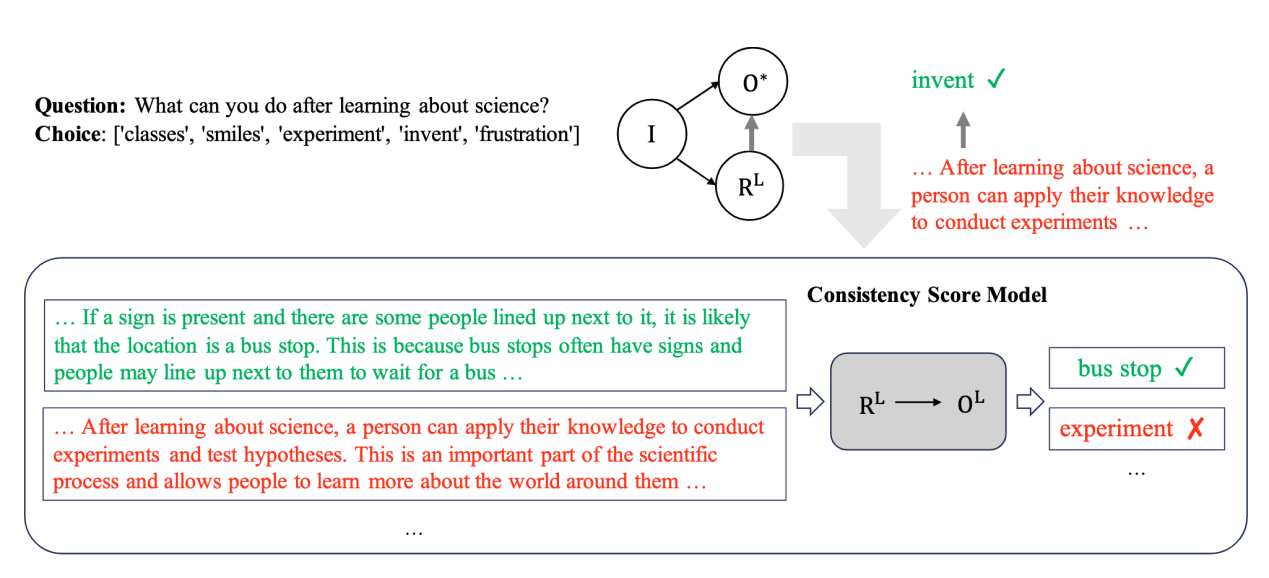
图2:大小模型知识蒸馏协同建模框架
★
Self-Improvement Programming for Temporal Knowledge Graph Question Answering
作者:陈茁,张钊, 李紫宣, 王飞, 曾宇涛, 靳小龙,徐勇军
内容简介:时序知识图谱问答旨在参考时序知识图谱来回答带有时间意图的问题。该任务的核心挑战在于理解问句中关于多种类型时间约束(如:在…之前、首次)的复杂语义信息。现有方法通过学习问题和候选答案的时间感知嵌入来隐式建模时间约束,难以全面理解问题语义。基于语义解析的方法则通过生成具有符号操作符的逻辑查询,实现对问题约束的显式建模。受此启发,本文设计了基本时序算子,提出了一种新颖的自我完善知识编程方法Prog-TQA。具体来说,Prog-TQA利用大型语言模型(LLM)的上下文学习能力来理解问题中的组合时间约束,根据给定示例生成相应的程序草稿。然后,使用链接模块将程序草稿与TKG对齐,最后执行程序以检索答案。为了增强对问题的理解能力,Prog-TQA采取了一种自我提升策略,使用高质量的自生成程序引导LLM理解复杂问题。实验证明,Prog-TQA方法在广泛使用的MultiTQ和CronQuestions数据集上取得了显著的性能提升。
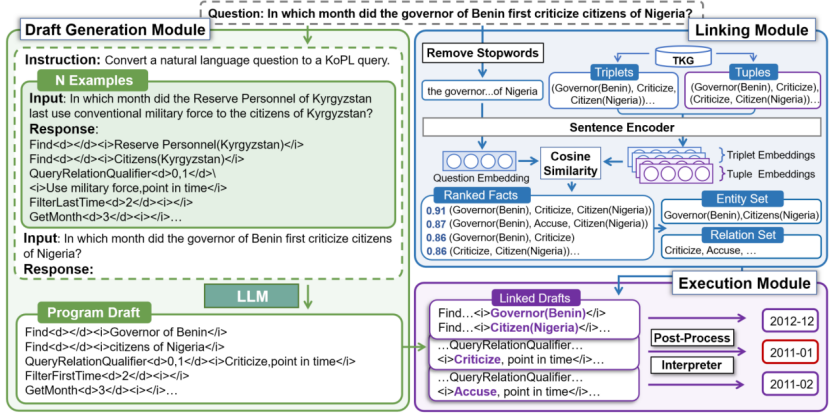
图 3:Prog-TQA时序问答框架
★
Class-Incremental Few-Shot Event Detection
作者:赵凯琳,靳小龙,白龙,郭嘉丰,程学旗
论文链接:http://arxiv.org/abs/2404.01767
内容简介:事件检测是信息抽取和知识图谱中的基本任务之一。同时,一个真实场景下的事件检测系统通常需要不断地处理新到来的事件类别。由于对大量未标注样本进行标注工作耗时耗力,因此这些新类别通常只有少量的标注样本。基于此,本文提出了一个新的任务,称为类增量少样本事件检测。然而,在这个任务中存在两个问题,即旧知识遗忘问题和新类别过拟合问题。为了解决这些问题,本文进一步提出了一种新的基于知识蒸馏和提示学习的方法Prompt-KD。具体来说,为解决旧知识遗忘问题,Prompt-KD采用了双教师模型对一学生模型的知识蒸馏框架,同时采用注意力机制来平衡这两个教师模型的不同重要性。此外,为了应对缓解小样本场景带来的新类别过拟合问题,Prompt-KD采用了基于课程学习的提示学习机制,通过在支持集样本后面拼接一个含有语义信息的指令,从而减少了对带标签样本的依赖。实验使用了FewEvent和MAVEN两个标准小样本事件检测数据集进行验证。实验结果表明,Prompt-KD模型在不同数据集、任务和学习阶段上均比基线模型有更好的效果,验证了该模型的有效性。

图 4:Prompt-KD模型示意图
★
Nested Event Extraction upon Pivot Element Recognition"
作者:任韦澄,李紫宣,靳小龙,白龙,苏淼,刘衍涛,官赛萍,郭嘉丰,程学旗
论文链接:https://arxiv.org/abs/2309.12960
代码链接:https://github.com/waysonren/PerNee
内容简介:嵌套事件抽取旨在提取复杂的事件嵌套结构,其中嵌套结构指一个事件递归地包含其他事件作为其论元。嵌套事件有一个核心节点称为Pivot Elements(PEs),其既充当外部嵌套事件的论元和内部嵌套事件的触发词,并将它们连接成嵌套结构。PEs的这种特殊特性给现有的嵌套事件抽取方法带来了挑战,因为现有方法不能很好地处理PEs的双重身份。因此,本文提出了一种新模型,称为PerNee,它主要基于识别PEs来提取嵌套事件。具体来说,PerNee首先识别内部嵌套和外部嵌套事件的触发词,并通过对触发词对之间的关系类型进行分类来进一步识别PEs。该模型还使用提示学习来整合事件类型和论元角色的信息,以获得更好的触发词和论元语义表征。此外,现有的嵌套事件抽取数据集(例如Genia11)局限于特定领域并且能触发嵌套事件的类型较少。对此,我们对通用领域中的嵌套事件进行分类,构建了一个新的通用领域的嵌套事件抽取数据集,称为ACE2005-Nest。实验结果表明,相比其他模型,PerNee在ACE2005-Nest、Genia11和Genia13上达到了最先进的性能,能够有效地抽取嵌套事件。
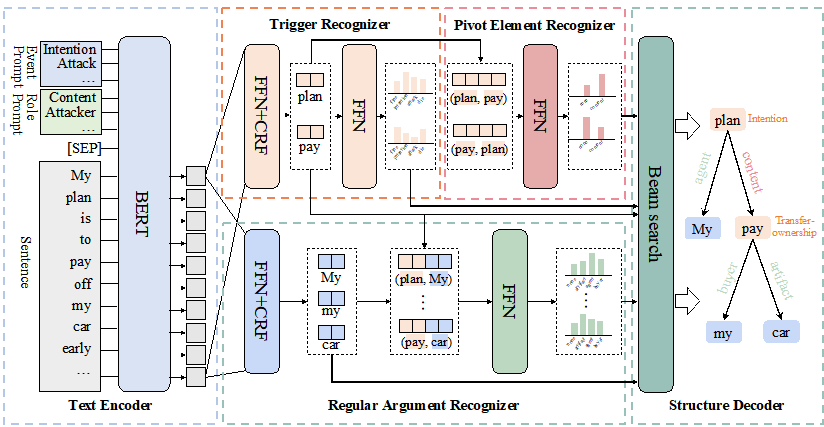
图 5:PerNee模型的整体框架
★
Few-shot Link Prediction on Hyper-relational Facts"
作者:隗继耀,官赛萍,靳小龙,郭嘉丰,程学旗
论文链接:https://arxiv.org/abs/2305.06104
代码链接:https://github.com/JiyaoWei/MetaRH
内容简介:超关系事件由主三元组(头实体、关系、尾实体)和辅助属性值对组成,广泛存在于现实世界的知识图谱中。超关系事件的链接预测(LPHFs)旨在预测超关系事件中的缺失元素,从而帮助填充和丰富知识图谱。然而,现有的LPHFs研究通常需要大量高质量数据。它们忽略了实例有限但在现实世界中却很常见的小样本关系。因此,我们介绍了一项新任务--超关系事件中的小样本链接预测(FSLPHFs)。该任务旨在预测超关系事件中缺失的实体,但关系的支持实例数量有限。为了解决FSLPHFs问题,我们提出了MetaRH模型,它可以学习超关系事件中的元关系信息。MetaRH包括三个模块:关系学习、特定支持集上调整和查询推理。通过从有限的支持实例中捕捉元关系信息,MetaRH可以准确预测查询中缺失的实体。由于目前还没有适用于这项新任务的数据集,我们构建了三个数据集来验证 MetaRH的有效性。在这些数据集上的实验结果表明,MetaRH明显优于现有的代表性模型。

图 6:MetaRH模型的整体框架
Selective Temporal Knowledge Graph Reasoning
作者:侯中妮,靳小龙,李紫宣,白龙,郭嘉丰,程学旗
论文链接:http://arxiv.org/abs/2404.01695
内容简介:时序知识图谱(TKG)预测任务旨在基于给定的历史事实预测未来发生的知识,近年来受到了广泛关注。目前,TKG预测任务已经在多个领域,如金融分析,灾难预警,危机事件响应等,展现出良好的应用前景。然而,这些领域通常为风险敏感的领域,错误预测或不可靠的预测会带来极为严重的后果。由于大量实体的历史交互非常复杂,相关知识的预测结果具有一定的不确定性。现有预测模型不加评估的输出其所有预测结果,其中不可避免地会输出低质量、甚至错误的预测,带来潜在风险。为此,本文提出TKG的选择预测机制,帮助现有模型进行选择预测,而非不加区别的进行预测。为了实现TKG的选择预测,本文进一步提出了基于历史的置信度估计器CEHis。CEHis首先计算已有模型预测结果的置信度,然后拒绝输出置信度低的预测。其中,CEHis考虑了两种信息,即当前预测的确定性和历史预测的准确性。实验结果表明,本文所提出的CEHis可以显著降低模型预测结果的不确定性,进而实现对预测风险的控制。
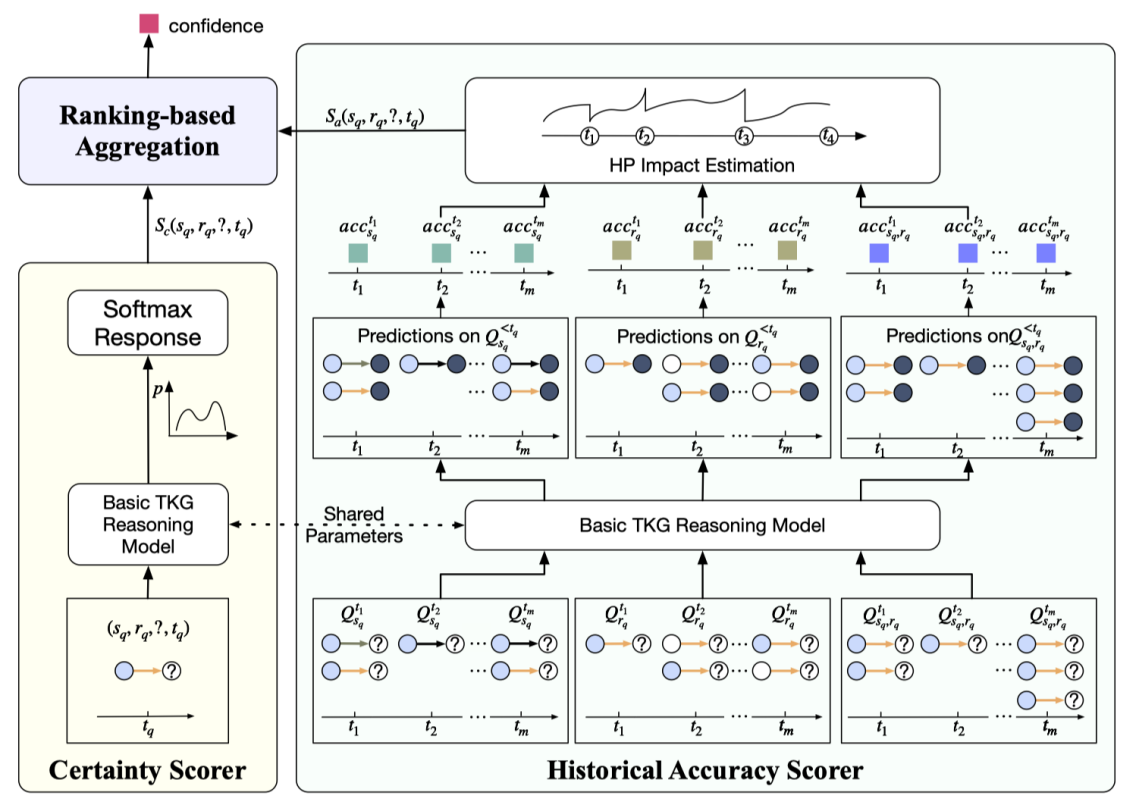
图7:CEHis模型示意图
Qsnail:A Questionnaire Dataset for Sequential Question Generation
作者:雷艳,庞亮,王元卓,沈华伟,程学旗
论文链接:https://arxiv.org/pdf/2402.14272.pdf
代码链接:https://github.com/LeiyanGithub/qsnail
内容简介:问卷是一种专业的研究方法,用于对人类观点、偏好、态度和行为进行定性和定量分析。然而,问卷的设计需要付出大量人力和时间,因此我们考虑让模型自动生成符合人类需求的问卷。问卷中包括一系列问题,要求能够满足涉及问题、选项和整体结构的精细约束。具体来说,问题应该与给定的研究主题和意图相关,具有明确性和针对性。选项应该针对问题进行定制,确保它们相互排斥,完备并且顺序合理。此外,问题顺序应该遵循逻辑顺序,如相关主题分组在一起。因此,自动生成问卷存在很大的挑战,主要是由于缺乏高质量的问卷数据集。为了解决上述问题,我们提出了 Qsnail,第一个为问卷生成任务专门构建的数据集,它包括来自在线平台上收集的13,168个由人类编写的问卷。进一步,我们在 Qsnail 上进行实验,结果表明,检索模型和传统生成模型并没有完全符合给定的研究主题和意图,相关性较弱。尽管大型语言模型与研究主题和意图更加密切相关,但在多样性和具体程度方面存在重大限制。即时通过链式思维提示和微调等方法对模型进行增强,语言模型生成的问卷仍然无法与人类编写的问卷相媲美。因此,问卷生成具有挑战性,需要进一步研究。
附件下载: