实验室5篇论文获SIGIR 2024录用

SIGIR 是中国计算机学会CCF 推荐的A类会议,在相关领域享有较高学术声誉。第47届ACM SIGIR信息检索研究与发展国际会议(The 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR 2024)计划于2024年7月14日- 7月18日在美国华盛顿召开。这次会议共收到 791 篇长文投稿,其中159篇长文被录用,录用率约20.1%。智能算法安全重点实验室(中国科学院)有3篇论文获 SIGIR 2024 录用,主题包括大模型检索增强、排序模型对抗攻击。
1、LoRec: Combating Poisons with Large Language Model for Robust Sequential Recommendation
作者:张凯科,曹婍,伍云帆,孙飞,沈华伟,程学旗
论文链接:https://arxiv.org/pdf/2401.17723
代码链接:https://github.com/Kaike-Zhang/LoRec
内容简介:序列推荐系统因其卓越的捕捉用户动态兴趣和项目转移模式的能力,在各种推荐场景中得到了广泛应用。然而,由于序列推荐系统的固有开放性,它们容易受到“投毒”攻击,即在训练数据中注入虚假数据以操纵系统的学习模式,例如推广特定商品。传统的防御方法主要依赖于针对已知攻击的假设或规则,难以有效应对新的或未知的攻击。为应对这一挑战,我们提出了一种创新的框架,将大型语言模型(LLM)中丰富的开放世界知识引入防御策略,以克服传统防御手段的局限性。在本文中,我们提出了LoRec,一个利用LLM增强的训练校准框架,以提高序列推荐系统在面对“投毒”攻击时的鲁棒性。LoRec包括一个LLM增强的校准器(LCT),该校准器利用LLM的知识优化推荐系统的训练过程,动态调整用户权重以减弱攻击的影响。通过引入LLM的开放世界知识,LCT能够将有限的先验知识或规则转化为更普遍的模式,有效防御“投毒”攻击。综合实验结果表明,LoRec作为通用框架,显著提高了序列推荐系统面向攻击时的鲁棒性。
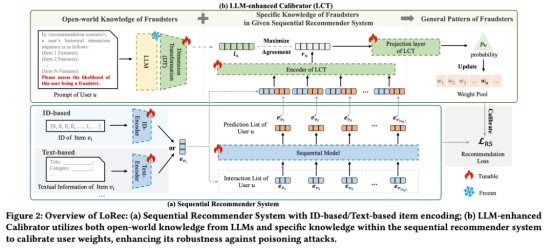
图 1:LoRec 框架图
2、Invisible Relevance Bias: Text-Image Retrieval Models Prefer AI-Generated Images
作者:徐士成,侯丹阳,庞亮,邓竞成,徐君,沈华伟,程学旗
论文链接:https://arxiv.org/abs/2311.14084
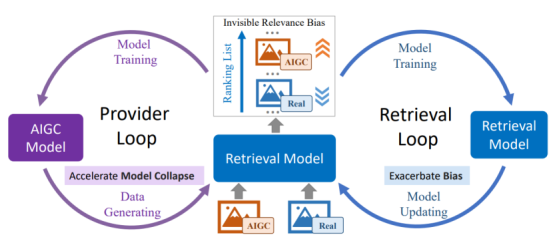
内容简介:随着生成模型的应用,互联网日益充斥着由AI生成的内容(AIGC),导致真实内容和AI生成的内容都被索引到搜索的语料库中。本文探讨了在这种情况下,AI生成的图像对文本-图像搜索的影响。首先,我们构建了一个包含真实图像和AI生成图像的基准测试,用于这项研究。在这个基准测试中,AI生成的图像具有与真实图像足够相似的视觉语义。对这个基准测试的实验揭示,文本-图像检索模型倾向于将AI生成的图像排在真实图像之前,即使AI生成的图像并没有比真实图像更多地展示与查询相关的视觉语义。我们将这种偏见称为无形的相关性偏见。这种偏见在不同训练数据和架构的检索模型中都被检测到,包括从头开始训练的模型和那些在大量图像-文本对上预训练的模型,包括双编码器和融合编码器模型。进一步的探索揭示,将AI生成的图像混入检索模型的训练数据会加剧无形的相关性偏见。这些问题导致了一个恶性循环,即AI生成的图像有更高的机会从大量数据中被暴露出来,这使得它们更有可能被混入检索模型的训练中,而这样的训练使得无形的相关性偏见越来越严重。为了解决上述问题并阐明无形相关性偏见的潜在原因,首先,我们引入了一种有效的训练方法来减轻这种偏见。随后,我们应用我们提出的去偏方法来追溯识别无形相关性偏见的原因,揭示出AI生成的图像诱导图像编码器将额外的信息嵌入到它们的表示中,这些信息使得检索器估计出更高的相关性分数。本文的发现揭示了AI生成的图像对文本-图像检索的潜在影响,并对进一步的研究有所启示。
3、Are Large Language Models Good at Utility Judgments?
作者:张恒然,张儒清,郭嘉丰,Maarten de Rijke,范意兴,程学旗
内容简介:检索增强生成(RAG)被视为一种有望缓解大语言模型(LLMs)幻觉问题的方法,近期受到研究人员的广泛关注。RAG很大程度上依赖检索到高质量的支撑信息,已有检索系统关注在问题和文档之间的相关性,而RAG的答案生成则需要进一步判断检索的文档对于问题的有用性。近期已有研究探索了LLMs对支撑信息相关性的判断能力,但缺乏对LLMs在支撑信息与答案生成的有用性判断的探索。为此,本文深入分析了LLMs在开放领域问答任务上的有用性判断能力。具体来说,我们设计了一套全面的有用性判断的基准测试,并对五种代表性的LLMs进行了一系列实验。实验发现:(i)ChatGPT 能够区分问题和文档之间相关性和有用性二者的不同;(ii)输入形式、输出要求以及输入顺序等因素对于大模型的有用性判断能力有较大的影响;(iii)对现有的稠密向量检索结果增加有用性判断比仅用相关性判断更能提高答案生成的效果。进一步的,我们设计了一种简单有效的 k-sampling 方法,能显著提高大模型的有用性判断能力,从而为答案生成提供高质量的支撑信息。
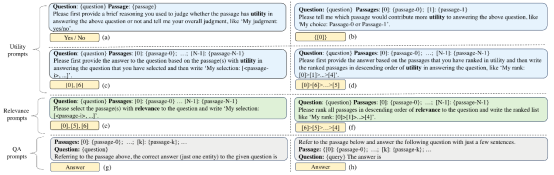
图 3:对大语言模型不同输入方式对应的指令示意图
4、Multi-granular Adversarial Attacks against Black-box Neural Ranking Models
作者:刘雨桉,张儒清,郭嘉丰,Maarten de Rijke,范意兴,程学旗
内容简介:对抗排序攻击因其能有效地挖掘神经排序模型漏洞并增强其鲁棒性而受到广泛的关注。传统的排序攻击方法采用单一粒度的扰动(词语级或句子级)来对目标文档进行攻击。然而,将扰动限制在单一粒度水平可能会降低生成对抗样本的灵活性,从而减弱攻击的潜在威胁。然而,直接引入多粒度扰动会面临组合爆炸问题,即攻击者需要在所有可能的粒度、位置和文本片段上识别最优的扰动组合。为了解决这一挑战,本文将多粒度对抗性攻击转化为一个序列决策过程,其中下一个攻击步骤中的扰动受到当前攻击步骤中扰动的影响。
具体地,本文使用强化学习来执行多粒度攻击,利用两个代理协作来识别多粒度漏洞作为攻击目标,并将扰动候选组织为最终的扰动序列。实验结果表明,我们的攻击方法在攻击有效性和不可见性的方面显著超越了现有方法,有力地揭示了现有的神经排序模型普遍存在的对抗脆弱性问题,能够促进鲁棒可信的信息检索系统的评价与建立。
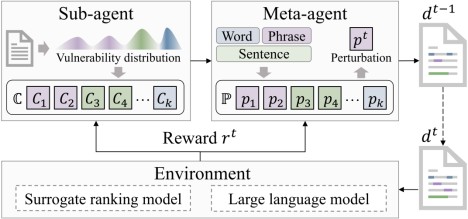
图 4:基于强化学习的多粒度对抗排序攻击框架
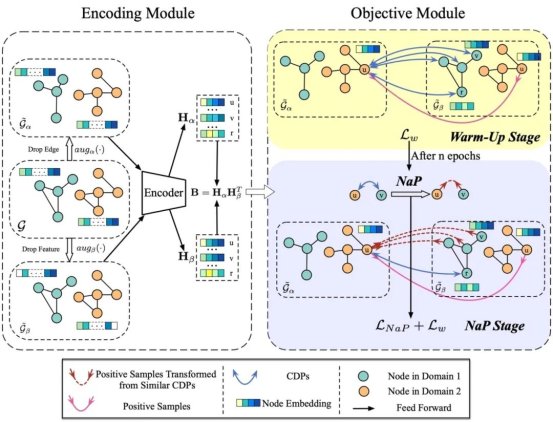
5、Negative as Positive: Enhancing Out-of-distribution Generalization for Graph Contrastive Learning
作者:王子旭,徐冰冰,袁一歌,沈华伟,程学旗
论文链接:https://doi.org/10.1145/3626772.3657927
内容简介:在这项工作中,我们发现传统图对比学习方法的分布外泛化能力有待提升。经过分析和验证,我们认为正是由于跨域对总被当作负样本,造成了域间的分布偏移被增大,最终降低模型的分布外泛化能力。基于此,我们提出将最语义上相似的跨域负样本对转化为正样本的方法即,Negative as Postive(NaP)。全面的实验表明,我们的方法NaP显著提升了图对比学习方法的OOD泛化能力。
附件下载: